
Als je –net als ik- veel tijd en moeite besteedt om je website te vullen met goede originele content, dan kan het frustrerend zijn om erachter te komen dat andere webbeheerders zo gemakzuchtig zijn geweest om jouw artikelen en afbeeldingen te dupliceren voor eigen gebruik. Vaak zonder vermelding van de bron.
Wat betekent dit voor je Search Engine Optimization (SEO)?
Ergens is het best vleiend als je content gekopieerd wordt, want dat betekent dat de ander jouw werk goed vindt. Maar de zoekresultaten in Google kunnen hierdoor dalen, wat leidt tot minder bezoekers en minder conversie zoals verkoop, verzamelen van handtekeningen, of opbouwen van naamsbekendheid. Om maar wat te noemen.  Vooral als de gedupliceerde content bijna nagenoeg hetzelfde is als jouw origineel (duplicate content), merkt Google dit al vrij snel en dit kan leiden tot minder hoge zoekresultaten. Google wil namelijk de best mogelijke gebruikerservaring bieden.
Vooral als de gedupliceerde content bijna nagenoeg hetzelfde is als jouw origineel (duplicate content), merkt Google dit al vrij snel en dit kan leiden tot minder hoge zoekresultaten. Google wil namelijk de best mogelijke gebruikerservaring bieden.
En ik weet niet hoe het met jou zit, maar als ik zoek, wil ik niet allerlei resultaten zien met vrijwel dezelfde inhoud. Want dan valt er eigenlijk weinig te kiezen. Dus maakt Google zelf een keuze uit jouw zorgvuldig geschreven webartikel én die van de ‘kopiisten**’, hetgeen NIET per definitie in jouw voordeel uit hoeft te vallen.
**Leuk detail (vind ik): de term ‘kopiist’ heeft in historische zin betrekking op een persoon die -voor de komst van de boekdrukkunst- boeken overschreef. Deze handeling werd vaak uitgevoerd door monniken.
Weet Google dan niet welk artikel het origineel is?
Je zou toch mogen aannemen dat de robots van Google weten welke pagina als eerste is geïndexeerd? Dat valt tegen. Google zelf beweert dat ze steeds beter in staat zijn om het origineel bovenaan te plaatsen, maar ik heb verschillende keren het tegengestelde gezien. Vooral als de andere site meer content bevat, vaak bezocht wordt en er naar gelinkt wordt door andere websites.
⚠️ Maar er is goed nieuws! Google pakt sinds 2024 ook sites aan die content van anderen herschrijven of vertalen met AI-tools, zonder toestemming. Zelfs als de tekst in andere woorden is gegoten, herkent Google patronen die wijzen op gekopieerde inhoud met weinig toegevoegde waarde. Zulke pagina’s scoren laag op expertise en betrouwbaarheid, en worden steeds vaker uit de zoekresultaten gehaald.
Hopeloze situatie? Of kun je er wat aan doen?
Gelukkig is het antwoord JA. Maar er is wel werk aan de winkel. Om te beginnen moet je natuurlijk eerst ontdekken of er ‘plagiaat is gepleegd’. Als een bepaalde webpagina belangrijk is, kun je bijvoorbeeld deze website gebruiken om te speuren naar duplicate content: https://www.copyscape.com/. Met Google Images of met Tineye kun je nagaan of je afbeeldingen op een andere site zijn geplaatst. Daarnaast kun je via de zoekmachine van Google op zoek gaan naar gekopieerde content.
Ik kan dat overigens iedere eigenaar van een website aanbevelen. Googel jezelf, je bedrijf, producten of dienstverlening regelmatig. Kopieer bepaalde zinnen van je tekst en plak die in de Google zoekbalk. Als je de tekst tussen haakjes zet, zal Google op zoek gaan naar exact dezelfde tekst. Om de meest actuele zoekresultaten te vinden, kun je gebruik maken van ‘Tools’->’Elke Periode’-> ‘Afgelopen maand’. Daarnaast kan het zinvol blijken om een kijkje te nemen bij ‘Afbeeldingen’.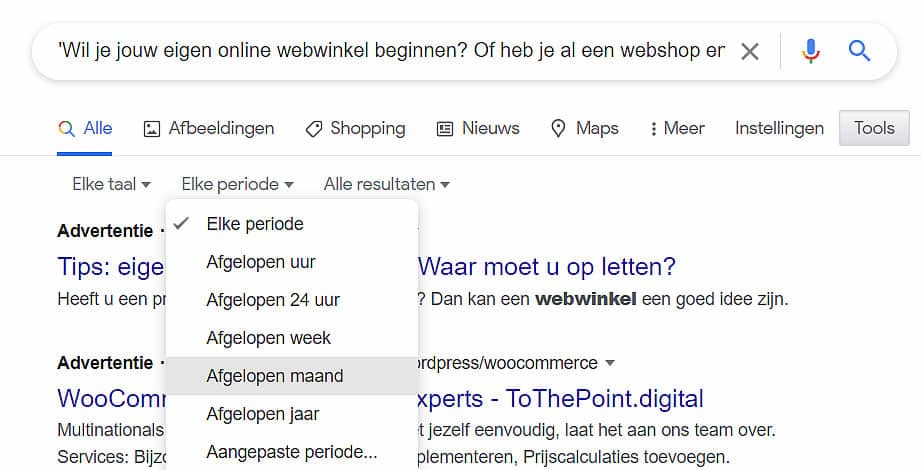
🔍 Hoe ontdek je dat je website is gekopieerd?
In dit artikel lees je al meer over methoden zoals het gebruik van Google en Copyscape. Hier zijn aanvullende tools en technieken:
- Google Alerts: Stel meldingen in voor unieke zinnen uit je content. Zo word je gewaarschuwd als ze elders opduiken.
- Plagiaatdetectietools: Gebruik tools zoals Grammarly’s Plagiarism Checker of Siteliner om duplicaten te vinden.
- Wayback Machine: Controleer of de kopie eerder online stond dan jouw originele content.
- SEO-tools: Platforms zoals Ahrefs of SEMrush kunnen je helpen bij het opsporen van duplicate content en backlinks naar gekopieerde versies.
Let op: Duplicate content kan onbewust ontstaan. Misschien doe je het zelf wel!
Als je een webshop hebt, kan het lastig zijn om voor elk product een unieke tekst te schrijven. Vaak zie je dat dan de teksten van de leverancier gebruikt worden. Aangezien een leverancier meer klanten heeft, die ook geen zin hebben om iets nieuws te verzinnen, zijn er uiteindelijk veel websites met gekopieerde content. De leverancier heeft hier  meestal geen enkel bezwaar tegen, maar zoals gezegd is het niet goed voor je ranking (SEO). Het kost meer tijd, maar als je er even voor gaat zitten, kan een originele beschrijving van een product je veel opleveren.
meestal geen enkel bezwaar tegen, maar zoals gezegd is het niet goed voor je ranking (SEO). Het kost meer tijd, maar als je er even voor gaat zitten, kan een originele beschrijving van een product je veel opleveren.
Duplicate content op de eigen site of die van een partner.
Dit kan ontstaan doordat een zelfde artikel meerdere URL’s heeft, bijvoorbeeld omdat het in meerdere categorieën staat. Daarnaast kan het zijn dat je bepaalde informatie ook op een andere site wil plaatsen. Zo heb ik de blog ‘Goede foto’s maken en aanleveren‘ gekopieerd en op de site van de Stichting Brabantse Beeldende Vrijetijdskunst geplaatst, zodat deelnemers aan een digitale expositie konden lezen aan welke voorwaarden hun foto’s moesten voldoen. Dankzij de plugin van Yoast, kon ik bij ‘geavanceerd’ een Canonieke URL invullen waarmee ik Google laat weten waar het origineel zich bevindt. Op deze site dus, kahlowebsites.nl.

Als ik van datzelfde artikel een te downloadbare pdf had gemaakt met exact dezelfde informatie, dan kan Google hier de voorkeur aan gaan geven. Om dit te voorkomen, kan ik de volgende regel plaatsen in het .htaccess-bestand:
Redirect 301 /pdf-fotos-aanleveren/ https://kahlowebsites.nl/fotos-aanleveren-website-webwinkel/
En dan blijkt je werk te zijn gejat. Wat nu?
Gelukkig laat Google je niet geheel aan je lot over, en kun je ze om hulp vragen. Maar ze eisen dan wel dat je eerst contact opneemt met de kopiist. Gaat deze niet in op jouw vriendelijke verzoek en overtuigende argumenten, dan moet je een DMCA-melding indienen bij Google: https://support.google.com/.
Wordt je content op grote schaal gekopieerd door een hardnekkige overtreder in Nederland? Dan kun je overwegen om contact op te nemen met stichting Brein.
In enkele gevallen is het heel lastig om te achterhalen wie de eigenaar van de website eigenlijk is. Dan kun je op sites als https://www.sidn.nl/ (WHOIS) de naam van de website invullen en vervolgens klik je op ’toon mij de gegevens’. Je krijgt vervolgens de domeinnaamgegevens te zien. Staat de eigenaar er niet bij? Neem dan contact op met het bedrijf waar de website is gehost.
✅ Wat kun je doen als je website is gekopieerd? Checklist.
Naast de reeds genoemde stappen in het artikel, overweeg het volgende:
- Bewijs verzamelen: Maak screenshots van de gekopieerde content, inclusief datum en tijd, en noteer de URL’s van de betreffende pagina’s.
Juridisch advies & contracten - Contact opnemen met de overtreder: Stuur een beleefde maar duidelijke e-mail waarin je verzoekt om verwijdering van de gekopieerde content.
- DMCA-verzoek indienen: Als de overtreder niet reageert, dien dan een DMCA-verwijderingsverzoek in bij de hostingprovider of zoekmachines zoals Google.
- Juridisch advies inwinnen: Overweeg om juridisch advies in te winnen, vooral als de gekopieerde content schade toebrengt aan je merk of inkomsten.
Kun je online diefstal van je foto’s en teksten eigenlijk wel voorkomen?
Slecht nieuws: dat is vrijwel onmogelijk. Uiteraard kun je wel het e.e.a. doen, maar het blijft altijd mogelijk een foto te ‘jatten’. Je leest er hier meer over.
Je online foto’s zijn sowieso niet geschikt voor print- of drukwerk.
Op een website -met een deskundige webmaster- worden de foto’s flink verkleind omdat een webpagina anders niet snel genoeg laadt. En als je een foto van maximaal 1200px breed online zet (wat al vrij breed is voor een site), is er hooguit een kleine afdruk van te maken, veelal in slechte kwaliteit. Uiteraard kan iemand die foto’s op de eigen website plaatsen, maar dat is te achterhalen via sites als Google Images of Tineye .
Wil je toch extra bescherming tegen diefstal?
Dan kunnen wij de ‘right click’-optie blokkeren. Toch blijft het dan nog steeds mogelijk een foto te jatten. Bijvoorbeeld door een screenshot te maken. Maar je maakt het veel mensen wel wat lastiger, zodat ze zullen afhaken. Robots zijn natuurlijk een ander verhaal omdat deze de code van de sites afstruinen.
 Heb je een WordPress-site? Dan kun je deze plugin gebruiken (klik hier).
Heb je een WordPress-site? Dan kun je deze plugin gebruiken (klik hier).
Het mooie van deze plugin is dat je hiermee ook jouw foto’s en teksten op een tablet of smartphone kunt beveiligen tegen opslaan!
Daarnaast kunnen wij op of onder je foto een copyrightmelding plaatsen. Zoals ‘© 2020 Naam v.d. eigenaar of bedrijf’. Dit heeft geen enkele officiële waarde maar mogelijk weerhoudt het anderen je foto ongevraagd te gebruiken.







Wat gebeurt er als iemand mijn content kopieert, maar een paar kleine dingen aanpast? Ziet Google dat als duplicate content?
Google kan kleine aanpassingen herkennen, maar als de kern van de tekst grotendeels hetzelfde blijft, kan het nog steeds als duplicate content worden beschouwd. Dit is vooral problematisch als de gekopieerde pagina op een site staat met meer autoriteit, want dan kan die hoger ranken dan jouw originele artikel. Daarom is het belangrijk om snel te handelen als je kopieën ontdekt en, indien nodig, gebruik te maken van een DMCA-melding om je originele werk te beschermen. In mijn blog lees je daar meer over.